Nvidia의 고위 연구과학자이자 AI 에이전트 계획의 주도인, Jim Fan의 TED Talk에서는 AI 에이전트에 대해 새로운 시각을 제시하였어요.
Fan은 '펀데이션 에이전트'라고 불리는 새로운 개념을 제안함으로써, 물리적 및 가상환경에서 원활하게 기능을 수행하는 AI 에이전트에 대해 설명합니다.
비디오 게임, 메타버스에서부터 드론, 인간형 로봇에 이르기까지 모든 것들이 펀데이션 에이전트로 대체될 것이며, 하나의 모델이 다양한 상황에서 이를 수행하는 방식을 사용할 수 있게 될 것이죠.
이러한 기술이 우리 삶의 많은 측면에 바탕이 되면서, 우리 삶을 크게 바꾸는 일이 될 것들을 Fan은 논의합니다.

Foundation Agent는 AGI와는 다르게 가상 및 물리 환경에서 다기능 작업을 수행하며, 다양한 영역에서 기술을 습득하는 다기능 AI를 개발하는 것을 목표로 한답니다.
Jim Fan과의 비공개 토론으로, Foundation Agent 및 인공지능 분야의 연구 논문에 대해 이야기하며, 그것이 향후 연구 및 개발에 기여할 것이라고 설명하고 있어요.
Foundation Agent는 입력으로 몸체 프롬프트와 작업 프롬프트를 받고, 출력으로 행동을 산출하며, 대규모의 실제 데이터를 통해 학습되며 모든 언어적 작업은 텍스트 입력과 출력으로 처리되는 개발 방식으로 진행된답니다.
조금더 자세한 설명을 듣고싶다면 Jim Fan의 TED 토크를 추천할게요!

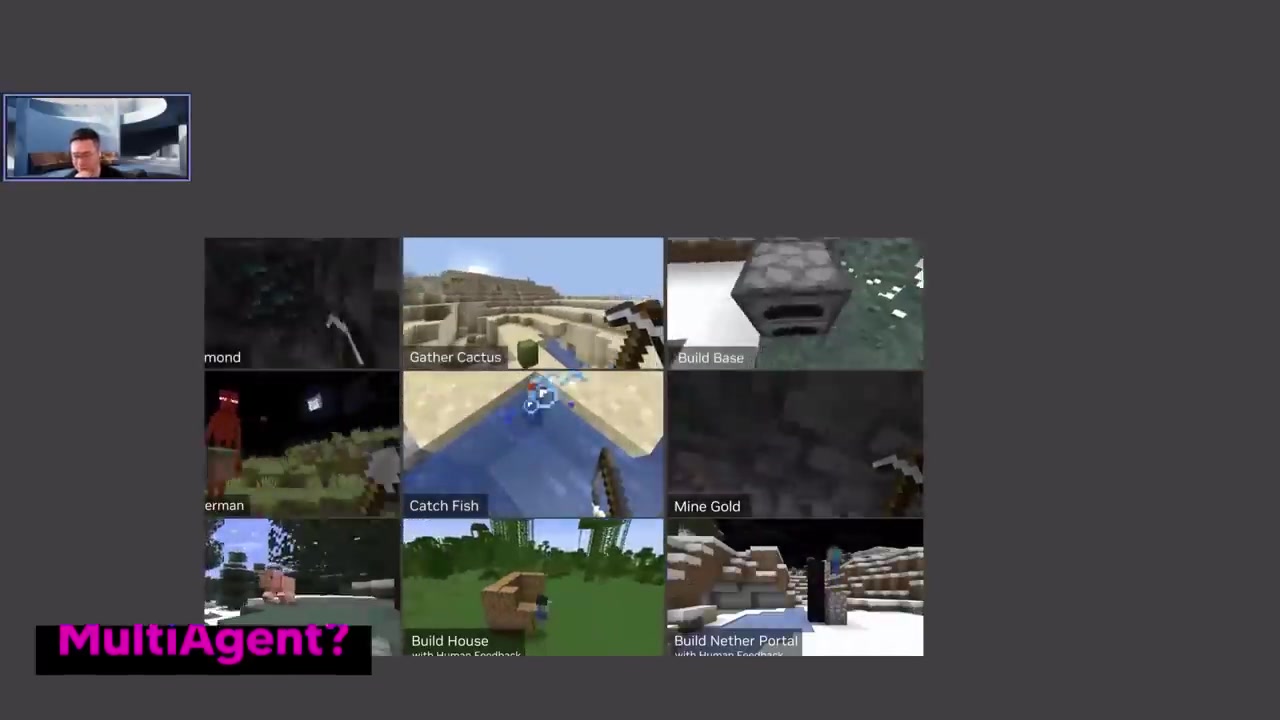
'보이저'는 마인크래프트라는 비선형 게임에서 사람의 개입 없이 여러 시간 동안 게임을 플레이할 수 있는 최초의 AI 에이전트이에요.
UK 인구의 2배가 넘는 1억 4천만 명 이상이 활동하는 세계에서 각광을 받는 게임 '마인크래프트'의 인기를 이용한 프로젝트예요.
영상에서 보이는 것처럼 보이저는 게임을 끊임 없이 즐길 수 있도록 굉장한 다양성과 자유도를 갖추고 있어요.
이러한 인공지능을 가능하게 하는 것은 바로 코딩이며, 그 뒤에 숨어있는 '코딩의 액션'이죠.

마인크래프트는 3D 월드지만 최강 에이전트 GBD4는 텍스트만을 인식해요.
그래서 우리는 3D 월드를 텍스트로 변환할 수 있는 JS API인 Mind player를 사용합니다.
Voyager는 GBD4 위에 설계된 알고리즘으로, GBD4를 활용해 자바스크립트 코드 스니펫을 생성해요.
Voyager가 코드를 생성한 뒤, 실제 게임 실행 시간에 실행되며, 프로그램이 항상 정확하지 않을 때는 자가 반성 메커니즘을 통해 개선하려고 해요.
자가 반성의 세 가지 소스가 존재합니다.

Voyager는 에이전트의 현재 상태와 세계의 상태를 고려하여 액션을 취하고 그 결과를 관찰합니다.
실행된 액션의 결과를 반영하여 더 나은 성능을 위해 다른 액션을 시도하고 반복학습합니다.
성숙한 스킬이 된 경우, 프로그램을 Skill Library에 저장하여 나중에 빠르게 호출할 수 있습니다.
GP4로 완전히 구동되는 코드베이스처럼 동작하며, Minecraft에서 탐험과 실험을 통해 자체 능력을 재귀적으로 구축할 수 있습니다.

코딩은 이중적으로 구성되어 있고, Voyager는 과거의 함수들을 조합하여 점점 복잡한 기능과 프로그램을 만들 수 있어요.
마인크래프트에서 에이전트가 배고픔을 느끼면서 음식을 찾아갈 때의 예시를 통해 Voyager의 작동을 설명하고, Voyager는 주어진 목표에 따라 새로운 도전을 찾기 위해 자체적으로 프로그램을 구현합니다.
Voyager는 무한탐색을 지속하며, 최대한 고유한 아이템을 획득하는 것을 목표로 합니다.
또한 Voyager는 계속해서 어려운 도전을 찾아 해결하기 위한 자체적인 커리큘럼도 구현합니다.

Voyager는 진행하면서 스스로 기술을 발견할 수 있어요.
그래서 현재 기능에 맞는 커리큘럼을 제안할 수 있게 된답니다.
게다가, Voyager는 진행의 연속으로 새로운 기술을 습득할 수 있는데, 사전 프로그래밍 없이 스스로 탐구한다는 점이 독특합니다.
다중 에이전트를 사용하는 것은 아직 프레임워크에서 지원하지 않는다는 단점이 있지만, 이를 통해 새로운 특성이 발견될 수도 있어요.
AI 기술에서 중요한 축은 'skill', 'embodiment', 'realities'입니다.
'skill'은 인공지능 에이전트가 배울 수 있는 스킬의 수를 의미하며, 'embodiment'는 해당 AI 에이전트가 제어할 수 있는 살아있는 몸체/로봇의 종류를 의미합니다.
마지막으로 'realities'는 에이전트가 다양한 시뮬레이션을 학습할 수 있는 수준을 말합니다.
따라서 목표는 AI의 능력과 제어 가능한 살아 있는 몸체의 종류와 시뮬레이션의 개수를 모두 확장하는 것입니다.

Voyager 프로젝트에서는 Minecraft와 같은 게임 환경을 사용하여 시뮬레이션 진행했어요.
이 게임은 오픈엔드 세계를 제공해 무한한 가능성을 가진 메타 시뮬레이션이죠.
이러한 Foundation model을 AI 개발에 적극적으로 활용하면, Minecraft에서처럼 무한한 가능성을 가진 오픈엔드 게임 및 로봇 시뮬레이션 등의 인공적인 시뮬레이션에서 보다 혁신적인 인공지능을 제작할 수 있을 것으로 보여요.

한 모델이 다양한 로봇들을 통제할 수 있는 기술을 확장해야 해요.
모델이 가상 및 실제 세계에서 다양한 규칙과 물리학을 습득할 수 있다면, 우리 현실 세계는 그저 100,000번째 현실에 불과해요.
우리 현실 세계가 실제로 시뮬레이션인 가설이 있는데, 이 아이디어를 AI를 구축하는 데 활용할 수 있다고 생각해요.
AI에게 우리 현실은 그냥 또 다른 시뮬레이션일 뿐이에요.

인공지능 시스템 디자인에 'Foundation Agent' 원리를 활용하며, 다음 세대의 실체 인공지능 시스템을 이 원리로 이끌 수 있다는 내용이에요.
데이터는 핵심 요소로, 스킬 습득은 기존 데이터에 의존합니다.
또한 Mind Dojo가 YouTube를 활용해 Minecraft의 움직임과 스킬을 학습한다는 이야기도 나와요.
이러한 기술 발전으로 앞으로는 기존 데이터에 의존하지 않고 스킬을 직접 배울 수 있는 인공지능 시스템이 등장할 것으로 예상된다고 합니다.

마인크래프트에서의 게임 활동에 대한 설명이 포함된 YouTube 동영상을 수집하여 이 데이터셋을 활용해 Mind Cue라는 모델을 학습시키려고 했어요.
Mind Cue 모델은 영상과 활동 설명에 대한 텍스트의 관계를 학습하고, 텍스트와 영상에서 일어나는 행동을 연결하는데 사용해요.
정확한 연결되는 경우는 점수가 1에 가까우며, 그렇지 않은 경우는 0에 가까운 점수를 부여하죠.
이러한 모델 학습을 위해 Mind Dojo에서는 수백만 시간에 달하는 마인크래프트 플레이 데이터셋 수집에 참여하였어요.
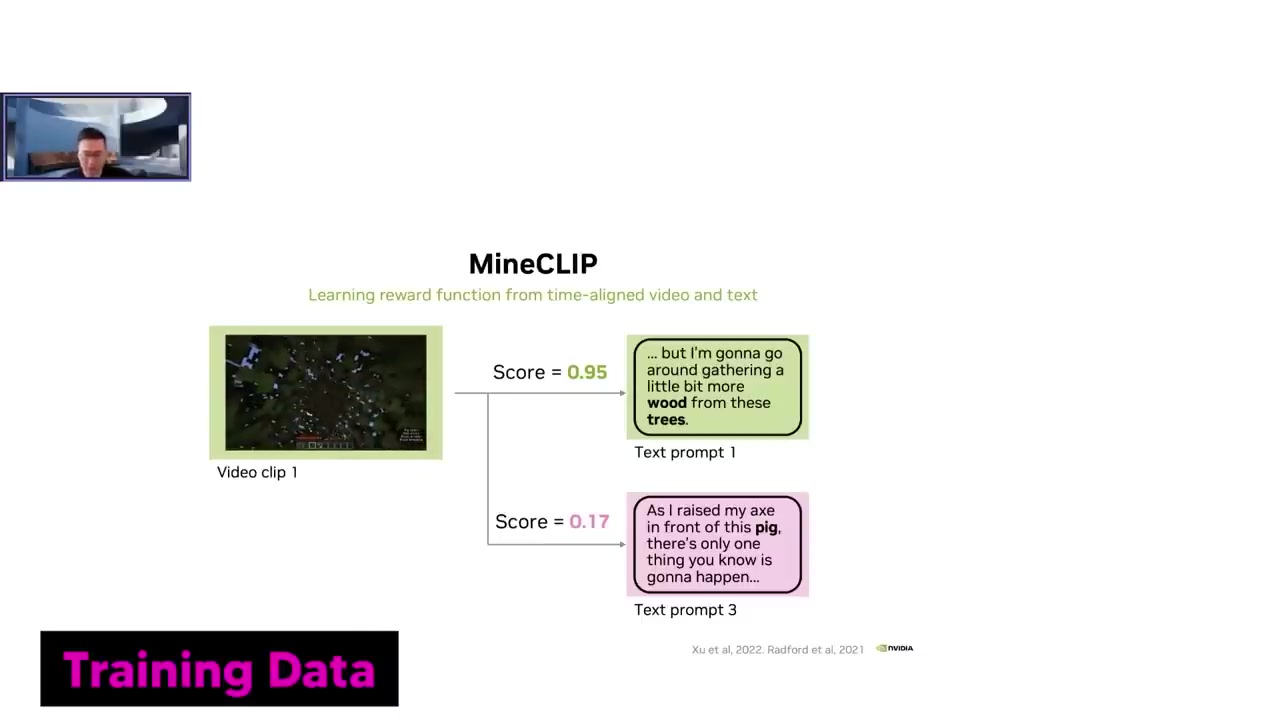
게임인 Minecraft에서 Reinforcement Learning을 사용해 에이전트의 행동을 학습하는 방법은, YouTube 동영상 데이터셋을 활용하죠.
이를 위해 에이전트는 과제를 수행하며 비디오 클립을 생성하고, 이 비디오 클립은 언어 데이터와 비교하여 점수를 출력해요.
이를 통해 행동이 과제와 일치하는 점수를 최대화하고, 이는 보상이 되는 Reinforcement Learning 루프가 되는거죠.
또한 비디오에서 시각적인 표현을 인코딩하거나 행동을 직접 학습하는 등 다양한 방식으로 비디오를 활용할 수 있어요.
하지만 Mind Dojo에서 사용한 YouTube 동영상 데이터는 사람의 행동이므로 AI에 의해 추출된 행동은 아니었어요.

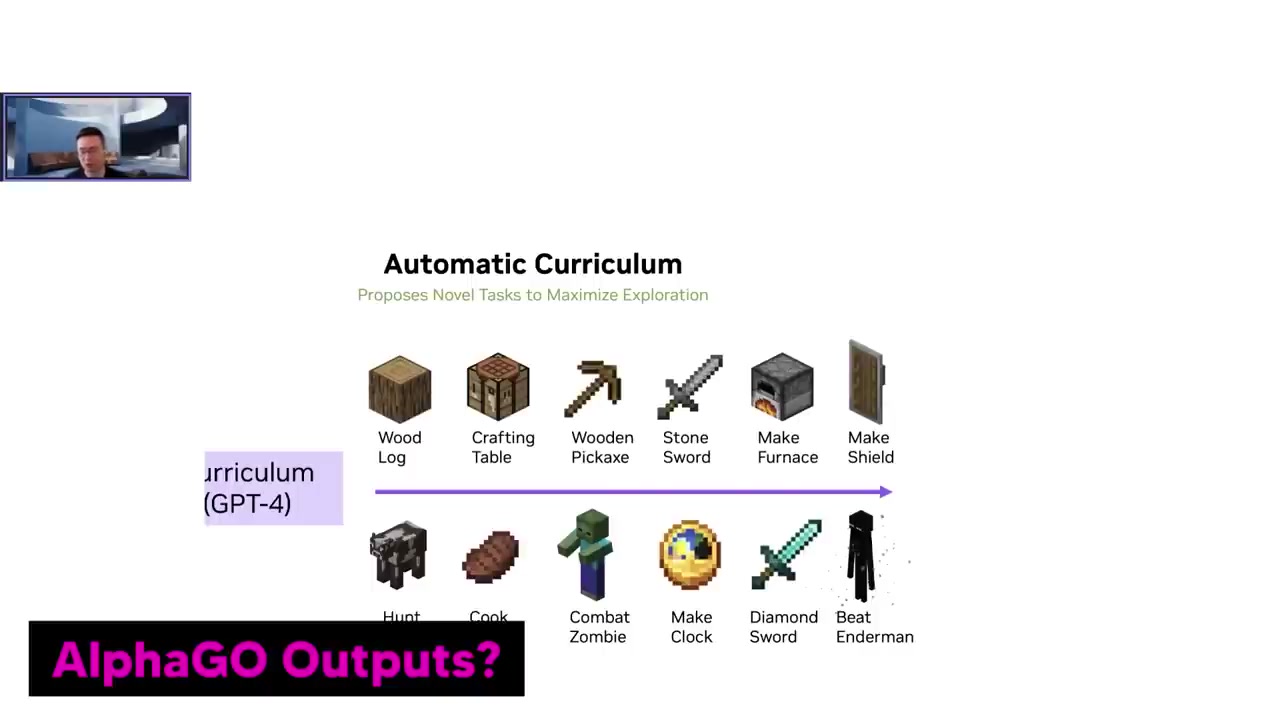
보이저에게 우리는 높은 수준의 지시를 줬어요.
즉, 얻을 수 있는 물체의 수를 극대화하는 것이에요.
그래서 보이저의 임무는 가능한 한 새로운 물체의 수를 극대화하는 것이에요.
또한 우리는 어떤 순서로 물체를 찾아야 하는지에 대해 알려주지 않았어요.
예를 들어, 다이아몬드를 찾기 전에 돌을 찾아야 한다고 말하지 않았어요.
단지 보이저에게 가능한 한 많은 새로운 물체를 찾아야 한다고 말했어요.
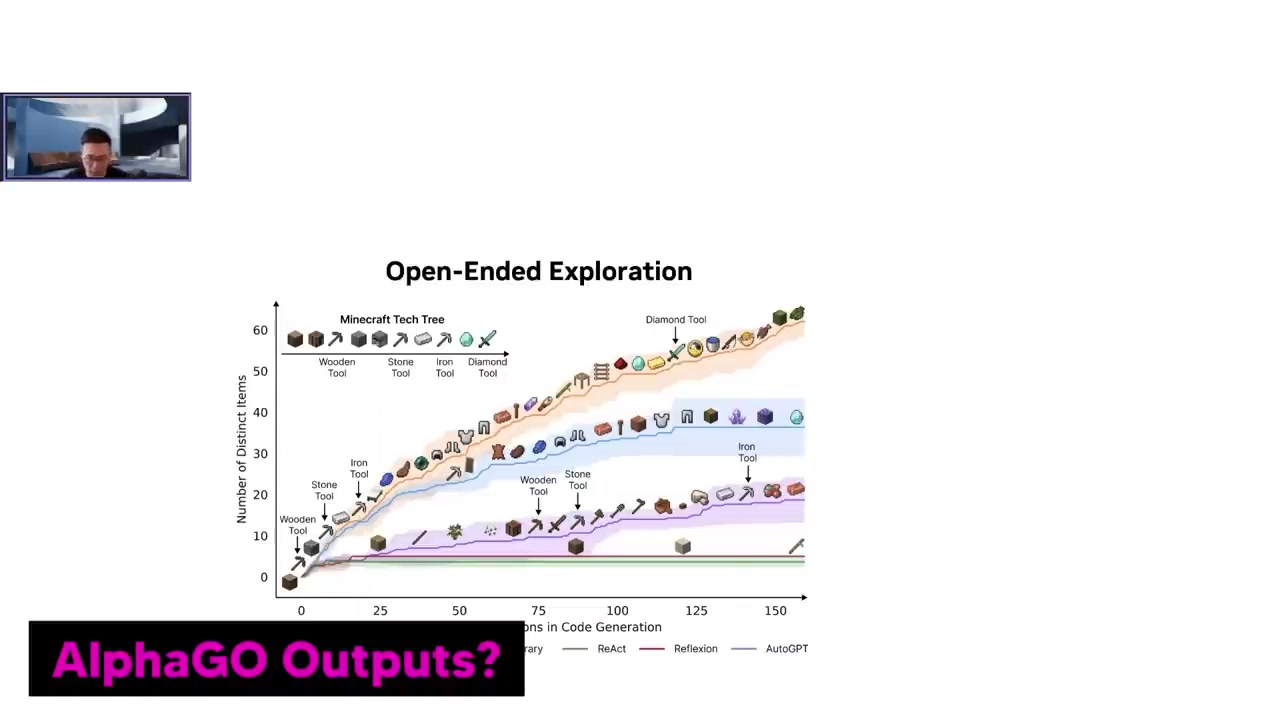
인공지능 Voyer가 수집할 수 있는 새로운 객체를 세어보고, 라이프사이클 내에서 다양한 아이템의 수를 계산함으로써 Voyer의 객체 수집 능력을 정량적으로 측정할 수 있어요.
X축은 프롬프트 반복 횟수, Y축은 Voyer가 발견하거나 만들어낼 수 있는 독특한 객체의 수이며, 블루 인텍스가 Skill 라이브러리가 없는 Voyer를 나타냅니다.
Voyer는 인간도 할 수 있는 대부분의 기술을 갖추고 있지만, 아직 컴퓨터 비전을 사용하지 않아 복잡한 구조물을 건설하는 데는 한계가 있습니다.
Voyer는 세계를 텍스트로 변환하기 때문에, 3D 좌표계에서 구조를 설계하는 것이 매우 어렵고, 인간도 어렵다고 해요.
따라서 Voyer는 구조물 건설 작업을 수행하지 않고, 이는 Vision 모듈의 한계와 Voyer가 구조물 건설 작업에 대해 훈련받지 않았기 때문입니다.
YouTube와 같은 코퍼스가 직관적으로 물리학적 규칙을 이해하는 강화학습 에이전트들에게 가치를 제공하는지 생각해보았어요.
이 에이전트들이 시뮬레이션 데이터와 실제 데이터처럼 여러 규칙들을 이해할 수 있을지 의문이에요.
그래서 '직관적 물리학' 이라고 부르는 것을 이해할 수 있는 모델을 만들어야 하는데, 이는 많은 비디오 모델을 훈련시켜야 한다는 문제점이 있어요.
그 이유는 비디오에는 '직관적 물리학'이 나타나기 때문이에요.
인간의 뇌는 예측 가능한 상황들을 해결하기 위해 직관적인 물리학적 지식을 활용해요.

현재 존재하는 에이전트들은 물리 법칙을 직관적으로 이해하지 못해서, 다음 일이 어떻게 전개될지 예측할 수 없어요.
직관적인 물리학을 습득할 가장 좋은 방법은 많은 양의 비디오를 보는 것이라고 생각해요.
하지만 물리 법칙만 이해하는 것으로는 부족해요.
차세대 에이전트가 되기 위해서는, 시뮬레이션과 비디오 학습을 통해 배운 물리 법칙을 실제 행동에 적용할 수 있는 연습이 필요해요.
Minecraft나 물리 시뮬레이션, 다른 게임 등 시뮬레이션을 통해 지식을 체득할 수 있으며, 오픈 엔드 에이전트를 시도해야 해요.
이러한 단계들을 통해 미래의 에이전트들이 발전할 수 있어요.

'Urea'는 'ISAC Sim'을 사용하여 Nvidia 시뮬레이션에서 펜 스핀 트릭을 수행하는 로봇 손이에요.
'Omniverse' 위에 구축된 'ISAC Sim'은 로봇학을 위한 라이브러리로, 로봇 손 모델, 입력 객체 등을 가져와 계산하며, 특히 높은 확장성이 있어요.
대단한 성능을 가진 이 라이브러리를 이용하면 실제로는 불가능한 데이터 수집 및 훈련을 빠르게 처리할 수 있어요.
그래서 실제 로봇으로 직접 훈련하는 것보다 더 빠르게 복잡한 펜 스핀 트릭과 같은 정책을 훈련할 수 있어요.
실제 'Urea'의 훈련은 언어 모델을 사용하여 물리 시뮬레이션 API에서 코드를 생성하는 외부 루프와, 보상 함수로 사용되는 두 번째 루프로 구성되어 있어요.
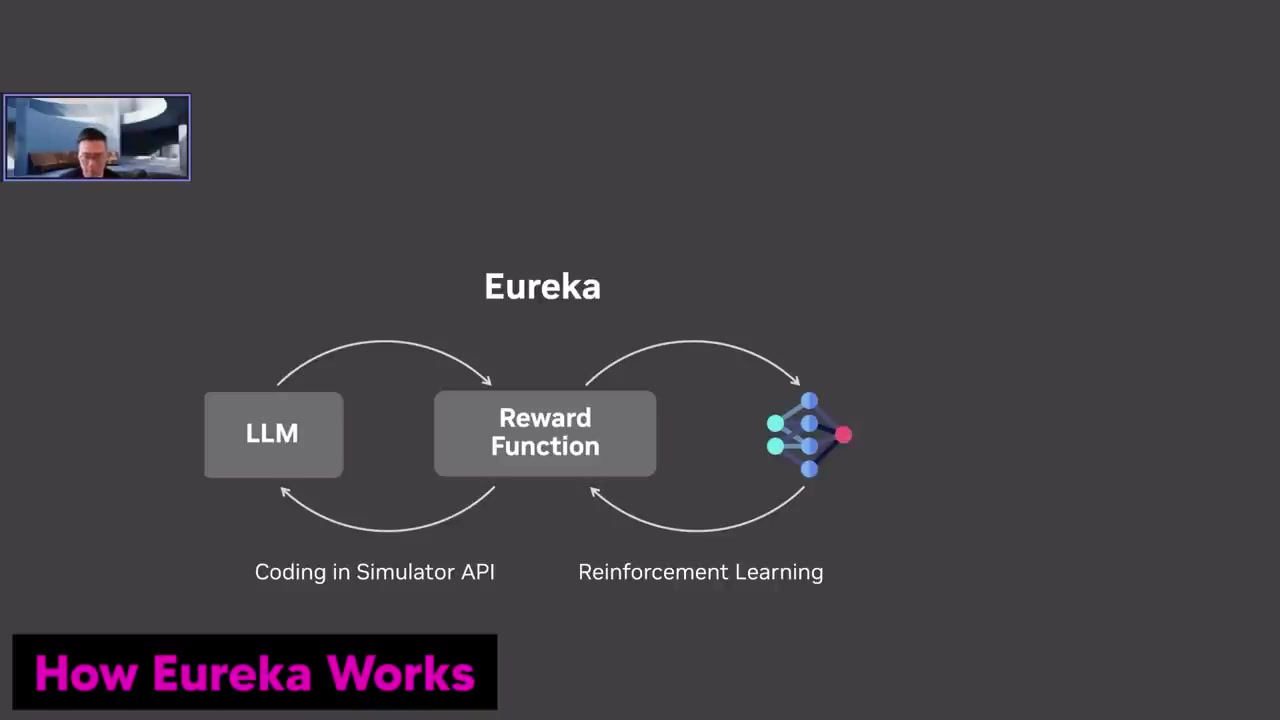
시스템 1과 시스템 2로 나눌 수 있는 손 모방 과정을 설명해요.
좌측의 L Loop는 시스템 2로, 손의 동작을 관찰하고 코드 변경을 제안하는 고수준의 추론을 수행해요.
우측의 루프는 시스템 1로, 빠르고 무의식적이에요.
이것은 회전시 추론을 하지 않고 진행되며, 감각과 같은 것으로 손의 기억을 활용해요.
오른쪽 루프는 더 작은 신경망인 시스템 1로, 손을 더욱 민첩하게 제어할 수 있는 더 높은 주파수를 가지고 있어요.
트리풀이라는 특정 예를 보여주진 않았지만, 이 방법은 일반적으로 적용 가능하며 펜 스핀뿐만 아니라 몇 가지 다른 형태의 수동 조작 작업에도 사용될 수 있어요.

강화학습을 이용한 로봇 훈련에서 리워드 함수를 매번 업데이트하며, 완전히 다시 훈련시키지 않아도 된다는 장점이 있어요.
이를 통해 본격적인 강화학습 트레이닝이 가능하며 리워드 함수 고도화가 가능해져 다양한 스킬을 훈련시킬 수 있어요.
로봇 훈련을 기반으로 실제 세계의 봇을 만들 수 있는 가능성이 있고, 로봇 분야에 집중하고 있기 때문에 이 분야에서 미래를 기대할 수 있어요.
이 뿐만 아니라, 다수의 GPU를 투입해 여러 개의 다양한 유형의 스킬을 병렬로 훈련시킬 수 있는 방법도 고민 중이에요.

다양한 작업은 각각 독립된 새로운 네트워크로 간주되며, 멀티태스킹이 가능한 네트워크 훈련이 다음 단계로 삼히고 있어요.
그리고 실제 세계에서 기능하게 만드는 것이 중요해요.
이를 위해 '심 투 리얼' 과정을 수행해야 해요.
시뮬레이션 가설과 관련된 도메인 랜덤화는 다양한 기술들 중 하나인데, 이것은 시뮬레이션에서 다양한 물리적 환경을 실험해 일반화하는 방법 중 하나에요.

작년에 발표된 'Ura'라는 연구논문은 로봇 개발의 자동화를 위한 L 사용하는 첫 번째 논문으로 알려져 있어요.
로봇의 보상 함수를 작성하는 것은 실제로 도메인 전문성이 필요한 작업이지만, 이 논문에서는 GPT-4의 능력을 이용하여 보상 함수를 자동으로 작성하죠.
GBD-4는 제로샷과 문서 이해능력이 탁월하여, Nvidia의 물리 API 문서를 제공하면 더 나은 퀄리티로 보상 함수를 작성할 수 있어요.
로봇 개발의 자동화는 현재 GPT-4를 통한 한 단계의 진전이며, 로봇 스택 전체가 우리가 아닌 GPT-4로 프로그래밍 될 수 있는지 기존 방법과 연속적으로 진행될 수 있는 흥미로운 질문이에요.

Language-instructed인 NLP-트레이닝이 들어간 AI 에이전트 Team이 Robot sim, Robot learning에 사용될 수 있어요.
하지만 로봇연구에서는 데이터 수집이 핵심 과제입니다.
데이터는 인터넷 비디오와 시뮬레이션 업스케일링에서 나올 수 있는데, 시뮬레이션적인 부분은 더욱 특별한 데이터 수집 방식이 필요합니다.
Mamba 라는 아키텍처가 Transformer를 대체하는 것은 가능하지만, 로봇연구에 있어서 현재는 핵심이 아닙니다.
'건강' 카테고리의 다른 글
| 새로운 연구에 따르면 일자리의 60%가 AI의 영향을 받을 것으로 전망(IMF 보고서) (0) | 2024.02.04 |
|---|---|
| AI가 일자리를 빼앗지 않는 이유를 보여주는 충격적인 보고서(새 보고서) (0) | 2024.02.04 |
| iOS 17.4! 사이드 로딩, 이모티콘 등을 포함한 새로운 기능! 그리고 유출된 아이패드 프로 세부 정보! (1) | 2024.02.04 |
| MagSafe VS Qi2? 뭐가 달라요! (0) | 2024.02.04 |
| 구글의 새로운 '텍스트 이미지 변환 모델'이 모든 것을 바꿨습니다(이제 출시되었습니다!) (0) | 2024.02.04 |
| 주요 AI 뉴스 #28 - Sam Altman의 놀라운 발언, Gemini Ultra 출시일, AGI "성취? (1) | 2024.02.04 |
| 팔월드에서 코인을 얻는 방법 (0) | 2024.01.29 |
| 맥이 계속 재시동되는 5가지 이유와 해결 방법 (0) | 2024.01.29 |



